12Sep2011
Before going into the details of the applications, I will explain further how Content Server processes code, mostly to show how it differs from other web programming engine like PHP or plain JSP.
Invoking ContentServer
You invoke ContentServer with the URL
http://www.yoursite.com/cs/ContentServer
Here http://www.yousite.com/cs/ can change according your domain name and where you have installed it, but the ContentServer servlet must be always invoked, and you have also to specify some parameters. The most important parameter is pagename.
As a general rule, you can assume ContentServer?pagename=Element invokes some code, written either in CSXML or in JSP. The specific code may require more parameters to process but the parameter pagename is the one you require to invoke the code.
But before going into more details, you have to know how the code is stored inside WCS.
First, let's introduce some terminology: within WCS code is called "Element". An element is either a pieces of JSP os CSXML code. Code is stored in a file inside the file system, but cannot be accessed directly pointing to it in the filesystem, as you do in PHP and JSP.
Indeed, there are some "metadata" associated to each element, and those metadata are stored in the database. So basically you have to read the database, and the database will tell you how to process the code.
There are 2 database tables involved : ElementCatalog e SiteCatalog. But before explaining those tables, I need to digress explaining how files in the filesystem are related to database tables.
A digression: tables with attachments
A database table for ContentServer is nothing really special, it is similar to any other table except there are a few conventions to be followed.
The first one is that every table managed by Content Server has at least the following 3 fields: "id", "name", and "description", and must be know to content server by registering it in the SystemInfo table (a special table used to index all the other tables in the system). ContentServer consistently create records with a name, assign then an id that is uniquely generated, require a name that is mandatory and offer the opportunity to store a description of the record.
Another important convention is that a table can have files attached. But instead of storing them as blob (whose usage is pretty inconsistent between different databases) files are actually stored in the file system, and only a pointer to the file is stored in the database table. The general convention is: when a field starts with "url" (or is just url) then its content is actually the relative path on the filesystem where is stored the file.
You may ask: relative to what? Well, as said the special table SystemInfo stores some informations for each table. In our case, it stores the base path for files attached to each table. So basically it works this way: when you need to attach a file to a database table, you need a field with a name starting with "url", then
- define in the SystemInfo table a folder where files for that table will be stored
- store in the url field the relative path name for the file
- store the actual file in the file system, using as a file name the top level folder defined in step 1, plus the value stored in the field as in step 3
The ElementCatalog and the SiteCatalog tables
So you now may wonder: what has this digression has to do with the ContentServer code processing? It is simple. The code to be executed is stored in a file attached to the table ElementCatalog as just described.
You can refer to each element with its name, but the name is used to locate a record in the ElementCatalog table. ElementCatalog stores informations like last modification time, and other stuff. Then, the actual file containing the code, is an attachment to the ElementCatalog table.
Please note that using the ElementCatalog, you can invoke that code from another element using internal calls like the ics:callelement call; but you cannot invoke the element from the servlet url with just its name in the ElementCatalog. This is both for protection and for caching.
But it is of course still possible invoking code from the ContentServer servlet, as I explained before, using the ContentServer?pagename=Element. Hovewer, the Element heade does not refer to an entry in the ElementCatalog table, but instead to an entry in the SiteCatalog table. In the SiteCatalog table there is a field linking to the actual entry in the ElementCatalog table, which in turn points to the actual code.
SiteCatalog actually has an additional purpose: caching elements. When you invoke something from the URL, the SiteCatalog is looked up but it does not necessarily call the underlying Element it points if it has already a cached copy available. Also SiteCatalog allows to create different entries for the same element, adding parameters for each of them, and eventually caching the output of the same element in a different ways.
How a request is actually processed
Let's recap the whole thing. This is how a content server request is actually processed:
- the user follows a link with an url containing ContentServer?pagename=Element, eventually with other parameters
- the whole combination of parameters is looked into the cache, and a suitable entry is available and (and is not expired), it is returned as a result, and the processing ends here.
- if the requested Element has not a valid cache entry, it is looked into the SiteCatalog table and the field rootelement is used to locate the actual element in the ElementCatalog table
- the ElementCatalog table is used in turn to locate the actual code; field url points the the code, concatenating its value with the top folder for this table (as specified in the SystemInfo table)
- Now the actual code is located on disk and it is exectued; in general an element does not produce a whole web page but only a small snippet. The code can in turn invoke other elements.
- Once the element has completed its work, the processed value is stored in the cache using informations from the SiteCatalog table
- Finally the result of the call is returned to the end user.
Please note again this is not yet the whole story. An url assembler can be invoked before ContentServer, actually hiding the pagename=Element parameter, an apache server can be in front of ContentServer, and a remote Satellite server can be used in front of the Apache+ContentServer combo to add another layer of caching. But I will talk about this later.
08Sep2011
We have seen that WCS is actually a layered system. Now it is time to go into the details of each layer to see which features they provide.
Content Server
The core of WCS is the Content Server layer. Although until recently the whole product has been called "Fatwire Content Server", actually Content Server is just the first layer. You actually call Content Server when you invoke the URL "/cs/ContentServer" (or "/servlet/ContentServer" or whatever your context path is)
ContentServer is basically an interpreter of an XML-based programming language developed before the year 2000 (presumably around 1995). It looks like the original developer wanted to implement a sort of custom ColdFusion-like but extensible programming language. I am familiar with the idea since at the time I built something very similar.
Content Server CSXML
At the time of the initial development of WCS, the new XML standard was very young, and its purpose was a bit unclear. The obvious idea was to use XML as a programming language, and using the custom tags programming constructs. I think so because I thought exactly the same thing.
Today I would say that it was not such a good idea mostly because XML is not really suitable to be a good programming language. I notice however that other CMS (for example, OpenCMS) works in the same way, and have a custom language based on XML.
The Content Server XML is not generic XML, but a sort of custom programming language that I will call it, not having a better name, CSXML. Later WCS added to the CSXML with something more standard, and more general: JSP, allowing programmers to use the more familiar Java programming language instead of a proprietary and somewhat limited programming language.
One funny thing in Content Server is that it still uses an XML parser, written in Java but developed by Microsoft! If you look to the jars in the WCS installation, you can still find the MSXML.jar. There was a time when Microsoft was Java friendly (they licensed Java and developed a version of Java for Windows for a while). Then they moved on... and C# is another story.
When XML came out, Microsoft developed one of the first XML parsers, an open source one, and it is the parser that still today ContentServer uses to parse his CSXML. Please note that the MSXML parser is not even standard compliant since it was developed before there was actually a standard for XML, and it has some oddities. It is not validating, and it has tag names case insensitive , but attributes are case sensitive...
CSXML is extensible, in the sense that you can develop custom tag libraries and invoke a tag. It is widely used in WCS since large part of the Xcelerate and Gator layers are developed in CSXML. You also need to use CSXML when you want to customize the interface.
Actually not everything in Content Server is implemented in CSXML. CSXML is a sort of scripting language to implement the user interface but all the underlying logic (especially the database access logic) is actually implemented in Java, packaged in jars and called through tag libraries. There are many tag libraries and only a fraction of them is actually documented for site development purposes.
Content Server JSP
CSXML is not the only way to develop for Content Server. There is also another, more standard, programming language available: I mean plain simple (and standard) JSP. So basically you have the choice of using CSXML to code your site and customizations, or use standard JSP (that of course allows you also to code the logic in pure and simple Java).
However, ContentServer is not just a plain JSP interpreter. It provides a lot of other services, that in CSXML are accessible through custom tags. The same is true also for JSP. The smart idea is that every tag defined for XML is available as a custom tag library for the JSP, with the same name and the same attributes.
So for example you can load an asset in CSXML using
<ASSET.LOAD TYPE="..." OBJECTID="..."/>,
bug you can do the same in a JSP using
<asset:load type="..." objectid="..."/>
Of course it is not just that in JSP you can use asset:load while in CSXML you use ASSET.LOAD. There are many other differences, in JSP you can use scriptlets, expressions like <%= ... %> and <% ... %>, while in CSXML you cannot, and you have to use a string replacement mechanism provided by CSXML for variables. For simpler things you can use CSXML but it becames easily too limiting. I am not going to go into the details however, since I consider CSXML leagacy and I will focus mostly on JSP.
06Sep2011
I am starting with this post a series that aims to be a tutorial on WebCenter Site (the new name of Fatwire Content Server).
In my plans, once completed you can use it as a gentle introduction to WCS, useful to be read before approaching the long (and complex) documentation. For this reason, I will focus more on the concepts and less on the details, leaving to the official documentation the task to delve into the specifics of every subject.
In this first post, I am just introducing some fundamental concepts of WCS.
WCS layers
It is not immediately obvious for anyone who have not seen the evolution of the product, that it is actually built of some different layers. This fact was more evident some time ago, when they were installed separately. Since now you install everything out of a single installer you may need some explanation to see those layers.
Knowing those layers is actually useful to better understand how WCS works. I am referring to those layers with their original name, because when you develop for WCS you will see them in the code: internally those names are still used.
Content Server
The first layers is Content Server in the proper sense. Although until recently the official name of the whole content management product was "Fatwire Content Server", in the original naming Content Server is only the first layer. Content Server is basically an XML based web programming language, similar (as a concept - not in the specific details) to ColdFusion, a web programming language that was "hot" at the time of the initial development of the product (around 1995).
Content Server was further extended adding to the XML based programming language (that is still there) a more powerful and more standard JSP based programming language. Both the XML and the JSP share the same underlying libraries, so everything that can be done in XML can be also implemented in JSP.
ContentServer however is mostly just an execution environment, with some features like security and caching, but it has no concept of assets, nor a proper user interface (except a very limited one used mostly to configure security). You can think to it like a sort of JSP engine, more powerful than just the JSP engine you can find in a standard application server, but definitely not an application.
It is the underlying engine used by the other components.
Xcelerate
When you use WCS, you normally expect to log into it and manage some content. Built on top of ContentServer, there is the Xcelerate application, that has a web user interface. Xcelerate is different from ContentServer since the former is built with the latter. Xcelerate also features a rich user interface, allowing to create and edit content.
Xcelerate implements the more important concepts of WCS: the Asset. There are some predefined assets like the Page and the Template, and more assets can be created. Xcelerate actually implements only the concept of Basic Asset, giving you the ability to create more basic asset definition using the Asset Maker. In the original design, Xcelerate is an engine good for developing even complex web sites but with having a content model that is pretty stable and not expected to be changed often.
Gator
A further extension of Xcelerate is Gator, that basically implements the concept of Flex Asset. Flex Asset were originally designed to easily implement e-commerce web sites. A typical problem of e-commerce is that the content model can be very complex and changed often, sometimes daily, so the Basic Assets were not enough flexible for this purpose.
Flex Assets fulfill the flexibility this requirement, providing the ability to change the content model easily, keeping the existing content safe, and allowing an easy update of the site, as simple as the publishing.
Publishing, normally used to just update the content, cannot be used to update the content model when using only basic assets. But you can update the content model using Flex Assets, and then just publish them to update the site.
Gator also implements the ability to customize the administrative user interface introducing also the concept of Attribute and Attribute Editor.
Engage
Another layer is Engage (once called "Marketing Studio") that further extends the feature set of the system, providing the ability to store attributes of the user (Visitor Attributes), build rules based on them (Segments) and generate content dynamically (using the so-called Recommendations and Promotion).
Everything else
The analysis is not actually complete: there are other components in the full system; they are built however on the same foundation but integrated, so I will stop the analysis here. I reserve to provide more details about the other components in a future post.
23May2011
When you create a flex family, you will actually create a number of assets peculiar for flex families: Attributes, Parent and Content Definitions (collection of Attributes), Parents (defined by a Parent Definition), Contents (defined by a Content Definitions). But you also have Filters.
So, while other components are pretty well known, Filters are a bit... underused, maybe because their function is not completely obvious.
A filter, basically, is a post processor for your content that is executed when you save or update a flex asset.
A filter is useful for functions like converting documents (for example extracting html from a Word document), analyzing a file (for example extracting information like the size and the type), or for strange features a bit technical like "creating an attribute corresponding to a standard asset fields". This feature is actually important, I will tell more about this in a future post.
Actually Filters are really powerful when used appropriately. The biggest problem is usually you have to code a Java class to implement a filter. But there are a few very useful filters, that can be used easily with no coding since they are already available.
Using the Thumbnail Generator
One of the more interesting filter is the Thumbnail Generator that is included with FirstSiteII but can be easily used in your site.
Thumbnail Generator Filter is contained in the firstsite-filter.jar that is usually deployed with Fatwire. The filter however could not be immediately available if you do not have FirstSiteII enabled (and on a production system usually you should not...). So please check if you have that jar available in your site. If not, get it from any installation with the FirstSiteII installed.
The filter must be enabled as well, registering it in the Filters register. That is, adding a row in the database table Filter as in the following picture:

Note the ThumbnailCreator entry is mapped to "com.fatwire.firstsite.filter.Imaging".
Once you have done this, you can create a filter for your FlexFamily.
Creating the filter
Create a new filter for your flex family. Once created, in the list of available filters, your registered filter should show up, like in this image:

Now the filter must be configured. The work is not yet done.
Actually, the problem with the Thumbnail Generator filter is exactly how to configure it appropriately. It requires:
- the input attribute (that should be actually a blob attribute)
- the output attribute (also a blob)
- the size of the thumbnail
- 2 integer attributes that will store the size of the original image
- 2 integer attributes that will store the size of the thumbnail
- optionally also an attribute for the "aspect" ratio (that is: is the image vertical or horizontal)
All the attributes are mandatory and if you make a mistake, you are in trouble because you get a very unfriendly and uninformative error message. To debug the filter you have to enable the property
com.fatwire.logging.cs.firstsite.filter=TRACE
in the file
cs/WEB-INF/classess/common-logging.properties
Error messages from the log are informative enough and can help to fix the filter. You can always look to the filter definition in the FirstSiteII as an help:

Assuming you have configured it correctly, now you have to attach the filter to a content (or parent) definition. The filter requires the input attribute you specified. You do not have to add other attributes as they will be added by the filter when you save it. But the corresponding attributes must exist in the family.
Once you have done it, give a look to the following image for the result.

PS I noticed the Thumbnail Extractor is using A LOT of memory and has the tendency to generate out of memory. Fatwire Support may provide a better implementation of the thumbnail extractor filter.
08May2011
I am often in charge of stress testing Fatwire sites for my customers. The tool of the choice for those missions is the wonderful Apache JMeter. In this post I wrote a small tutorial about using it to stress test a Fatwire site.
Well, the site I am going to stress test now is just FirstSiteII, running in a JumpStartKit: not exactly a real-world case. Nonetheless I think the post is both instructive and useful, since the used techniques can be applied on real sites with no changes.
Preparing a test script
JMeter installation is easy: just download the tarball, unpack it and double click on the jmeter.sh or jmeter.bat launcher script.
Preparing a test is easy as well: you just navigate the site with JMeter configured as a ProxyServer: it will intercept all the requests and create a script that can be run by a large number of parallel threads.
You can create a test manually if you want, but recording browser behavior is faster. So, here is a step by step guide to record a test using a JMeter proxy server.
First, add a Thread group to the Test Plan (it will be the target of our recording): click right button on Test Plan, then Add | Threads (Users) | Thread Group.
Second, create in the workbench an HTTP proxy server (click right button on Workbench, then Add | Non-Test Elements | HTTP Mirror Server).
Now you have a target and proxy server, and you can configure the proxy as in following image:
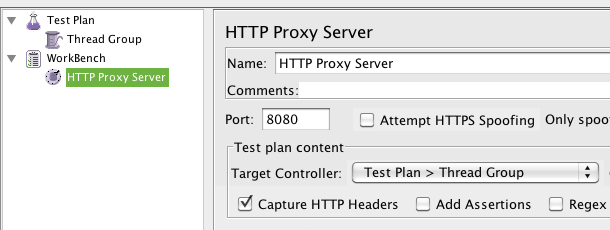
We can see JMeter Listening in port 8080 as a Proxy Server, capturing all the requests and storing them in the Thread Group we created in the Test Plan. Note: change port if you have tomcat in port 8080! I usually have it in port 7001 but it depends on the version of your JumpStartKit.
The Thread Group is the entry point to manage requests that can be run as parallel threads, so it is vital for our stress test effort. We will see more on this later.
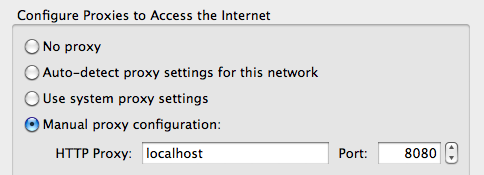
Third, you can configure a Firefox to use JMeter as a proxy server. You can use any other browser, it just happens I love FireFox. See the image below for the firefox configuration; with other browsers you mileage may vary.
Don't forget to remove "localhost" from the "No Proxy" field (that is enabled by default)!
Ok, we are ready. You can navigate the site to record the test. I used First Site II and navigated all the pages in the top menu (without going into the detail page). The result is shown below:
Now, I am almost ready to run a test, but since grouping of results is based on the names of the pages, I decided to separate Blob requests from Page requests. Also I grouped Util call (small elements calls) from full Page requests.
Basically I went through all the recorded entries and I renamed the requests to Page, Blob and Util depending on the parameters.
Now I am ready to perform a stress test. Well, actually I am going to perform a number of stress test with different number of threads (that simulate the number of different users).
Stress Testing FirstSiteII
Basically, in a stress test you have to check what is going to happen when there are 1, 5, 10, 20, 100, 1000 users accessing your site at the same time. So what I did is to run the test script changing the number of threads. This is basically just changing a parameter in the Thread Group configuration.
The first test run just with a single thread. It gives a measure of the absolute performance of the site. So I configured the Thread Group as follows:
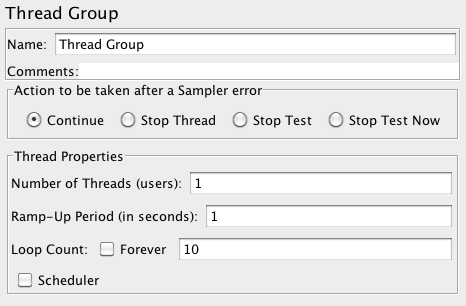
Running with those parameters gives the following results:

Note that repeating the test usually it does not give EXACTLY the same results but normally they are similar.

Basically, this test says that with a single user, JumpStart can deliver more or less 1 full page per second and serve up to 7 requests per second (including images and sub elements of a page). Note that a page is served on average in a second.
Increasing Concurrency
A single user, accessing a site and opening pages like a mad is not anyway a real model of the real world usage. What we really need to know is what is going to happen where there are more users accessing the site at the same time. So I increased the number of concurrent users.
If we try with 5 users we get a better result:
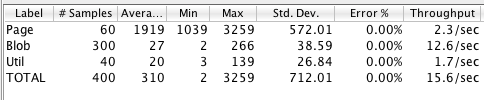
An application server has normally some capacity to handle concurrent request that we are exploiting.
Note the throughput with some concurrent users is higher, 2 full pages and 15 requests served per second, but a single page on average takes 2 seconds to be delivered...
Let's test with 10 users now:
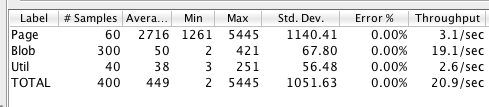
Better throughtput, 3 full pages per second and 2.5 seconds to get on average a full page. This is more or less the optimal result with a single site running on Fatwire Jump Start using Hypersonic SQL as database.
Note that we cannot add users and get better results forever however. With 20 users we don't improve anymore:
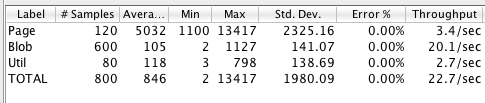
Throughput is the same as before (3 pages per second) but the average time to render a page is 5 second! The site is overloaded and is becoming slow.
Let's stress it a little bit more: 40 users!

Now, you get even less throughput than before, but you have to wait more to 10 seconds on average to get a page. If you try to navigate the site under stress the user experience is a slow site taking a lot of time to render pages.
Definitely, the site limit of our setup (completely unrealistic however) is around 10-15 users and you need to add Satellite Servers to horizontally scale the site.
17Apr2011
Recently, in the independent Fatwire Developer Yahoo Group someone was asking how to get symbolic URL instead of numeric ones. Since I have a good experience writing URL Assemblers, I decided to write a blog post about improving the more commonly used URL Assembler: FistSiteII url assembler.
FirstSiteII url assember and its limits
When writing a custom URL Assembler for FatWire, the normal starting point is the FirsSiteII URL assembler that is provided by Fatwire as an example.
A common complaint about the FSIIAssembler is generated URLs looks like this:
http://localhost:8080/cs/Satellite/FirstSiteII/FSII/Product_C/123445678/12345679
They are certainly more friendly than the "c=Product_C&cid=12345678&p=12345679" generated by default (using the QueryAssembler, actually), but they are not yet very useful for SEO, since there meaningful informations required by search engines are still missing from the URL.
So I will show in this post how to improve the FirstSiteII URL assembler to replace numeric ids with symbolic names, in order to get URLs like this:

In an ideal world I can released the full changed code for the fixed URL Assember, but as far as I know this code is proprietary, so I cannot release it with my modifications. If someone from Fatwire is willing to give me the authorization, I will make all the code available.
In the meanwhile however, I wrote an helper class where the bulk of the code goes, and I can release it os github since it is all my code. The code is now part of the FatStart project, and it is available here: AssemblerHelper source code.
So basically, getting that class and following my instructions you should be able to easily duplicate my efforts, as long as you can get the FSIIAssember source code from Fatwire (and as a regular Fatwire customer, you can just ask the Support).
What AssemblerHelper does
The underlying idea of the AssemberHelper is replacing cids with asset names. So for example, instead of using the cid 1234568 for the page named FSIIProducts, in the url there will be exactly FSIIProducts. This replacement can be applied (or cannot applied, depending on your preferences) to the parameter p as well. I have done it but it is not strictly required.
AssemblerHelper provides 2 static methods:
- name2cid(c, cid)
- cid2name(c, name).
The "c" (the current asset type) is always required since you need to query for the "name" field by the "cid" in the "c" table. When you do the reverse, it is still a lookup in the "c" table for the id of a rows with the given "name".
Actually, uniqueness of names is no more enforced in all the versions of Fatwire, so there is the danger that a cid cannot be replaced with an UNIQUE name. So in the code there is a provision that when a name is not unique, no replacement is done (name2cid will return the numeric cid instead of the corresponding name).
The resulting name is also URL encoded, so if can be used in URLs. Furthermore, since there is the danger of SQLInjection, I added some code to detect quotes and to filter out dangerous URL to reduce the risk.
The decoding method (name2cid) will translate a symbolic name back in as a numeric c, searching for the id of an asset of the given type with that name. The method will take care of the url decoding as well.
Adding the encoding to the FSIIAssembler
Once you have the AssemblerHelper code, you got the FSIIAssembler code, there are only a couple of modification required in order to use my AssemblerHelper.
In the getPath method the url is built concatenating some elements. The current cid is stored in data.cid, the current p is stored in data.p, and current c is stored in data.c
Locate the code that builds the returned path (it is easy, as long as you can read Java) and replace references to data.cid with AssemblerHelper.cid2name(data.c, data.cid) (you need an"import com.sciabarra.fatwire.*" in your source code as well).
If you want to replace also the ∫with a simbolic name, you have to add also AssemblerHelper.cid2name("Page", data.p).
That is all for the encoding.
Adding the decoding to the Wrapper Page
Fatwire actually do the decoding in the SatelliteServer. Since the decoding requires access to the database, it cannot be performed on remote Satellites. For this reason, the actual decoding of the name back into a cid is performed in the wrapper page.
However, before adding the decoding in the wrapper page, an additional modifications must be done in the FSIIAssembler. There is a check that cid and the p are actually numeric in valueOf method of the inner class FSIIAssemblyData. Since now the cid and p can be string, that check must be removed. So, just locate the exception surronding the Long.valueOf(cid) and comment it out. Do this also for the Long.valueOf(p) if you have replaced also the p with a symbolic name. That is all for the URL assembler.
Now it is time to add the conversion from the name to an id in the WrapperPage. Open the FSIIWrapper CSElement and look for the render:satellitepage tag. Replace arguments
<render:argument name="cid" value="<%=ics.GetVar("cid")%>"/>
<render:argument name="p" value="<%=ics.GetVar("p")%>"/>
with
<render:argument name="cid" value="<%=
com.sciabarra.fatwire.AssemblerHelper.name2cid(ics.GetVar("c"),ics.GetVar("cid"))%>"/>
<render:argument name="p" value="<%=
com.sciabarra.fatwire.AssemblerHelper.name2cid("Page",ics.GetVar("p"))%>"/>
And now you are done.
Notes on performance
This solution is a potential performance killer since it performs a query for each URL requests. Fatwire has a ResultSet cache, so this problem could be not an issue, but if it is (maybe because there are too many different requests so the query cache cannot cache enough result sets) my suggestion is to add an additional caching level, storing name2cid mapping in an HashMap. I would use a WeakHashMap (so memory won't be an issue) and store the hash map in the application context, but I have not tried this solution so far. It is left as an exercise for the reader...
07Mar2011
You already use assets types... so you already have the force with you!
But sometimes asset types are just not enough. So you have to learn how to use the force better.
For example, let's assume you have a lot of Page, but those Pages should be rendered in different way, if they are placed in different location of the siteplan. So which implementation strategy are you going to use?
I have seen a lot of different solutions to this problem, very often involving complex logic on the siteplan or extra parameters.
If you use the position in the siteplan, it can break easily, while extra parameters are a pain in the ass when it comes to caching.
Actually, the correct solution is to use subtypes. More in the detail:
- create a subtype for the different page renderings,
- select the subtype when you create a page
- use the subtype to dispatch to the correct rendering code.
Create a subtype and assign it
Go into the Admin panel, select Page and open it: you will see the subtype node; this will give you the opportunity to add a new subtype:

Now, when you create or edit a page, you can now see a pull down allowing to choose your subtype:

Recognize the subtype in the code
Now you can forget about passing spurious parameters or complex siteplan logic. When it comes to to render a page, read the subtype with asset:getsubtype, the call a different template according to the subtype. For example (look at the bold code):
<asset:getsubtype
type='Page'
objectid='<%= ics.GetVar("cid") %>'
output='subtype'/>
<render:calltemplate
tid='<%= ics.GetVar("tid") %>' site='<%= ics.GetVar("site") %>'
c='<%=ics.GetVar("c") %>' cid='<%=ics.GetVar("cid") %>' slotname='Body'
tname='<%=ics.GetVar("subtype")+"/Body"%>'>
</render:calltemplate>
This is a typical case for a "Body" template; if you have defined Home and Body subtypes, the code will dispatch to an "Home/Body" template and a "Content/Body" template according to the subtype of the page.
24Feb2011
Confused by the names of the various elements of a flex family?
It is actually pretty simple.
In a flex family you have basically contents (e.g. fp_C) organized in categories (e.g. fp_P) or parents.
You can define many subtypes for contents and parents. Those subtypes are called Content Definitions (e.g. fp_CD) and Parent Definitions (e.g. fp_PD). There is an asset to define each subtype of a content and an asset to define each subtype of a parent.
A definitions is basically a collection of attributes, so you define as the first step the attributes (e.g. fp_A) then group them in definitions.
Finally, there are filters (e.g fp_F). They are used to apply some post processing to assets when they are created or updated. For example copying fields, image resizing to create thumbnails, etc.